We’ve had an idea to make Slant an order of magnitude more useful. Before I get into the idea some context.
In my current conceptual analysis “comparison data” can have the following attributes:
- Comparability or uniquness
- Qualitative (needs descriptions) or Quantitative (just numbers) or Boolean (yes/no)
This is manifested into the following types of data that have the above attributes:
- Comparable Qualitative Data - Descriptions of build quality across laptops
- Comparable Quantitative Data - Price
- Unique Qualitative Data - Features like “any do moment” that are completely unique to a particular option.
- Unique Quantitative/Boolean Data - Outlying specifications like the cheapest or the lightest or the only option with github support.
On Slant we have two data types.
- Pros/Cons - Designed for qualitative data
- Specs - Designed for quantitative and boolean data
Obviously we’re missing some nuance in our data types.
We currently do a passable job with:
- Comparable Quantitative Data - Specs!
- Unique Qualitative Data - Pros/Cons are great for these.
- Unique Quantitative/Boolean Data - These outlying specs make decent Pros/Cons. A better system would tie the pro/con to the quantitative spec so you can confirm that none of the other options have that attribute. Our system breaks pretty hard when the data changes too (another option adds Github support). That said, our current way of handling this is passable IMO.
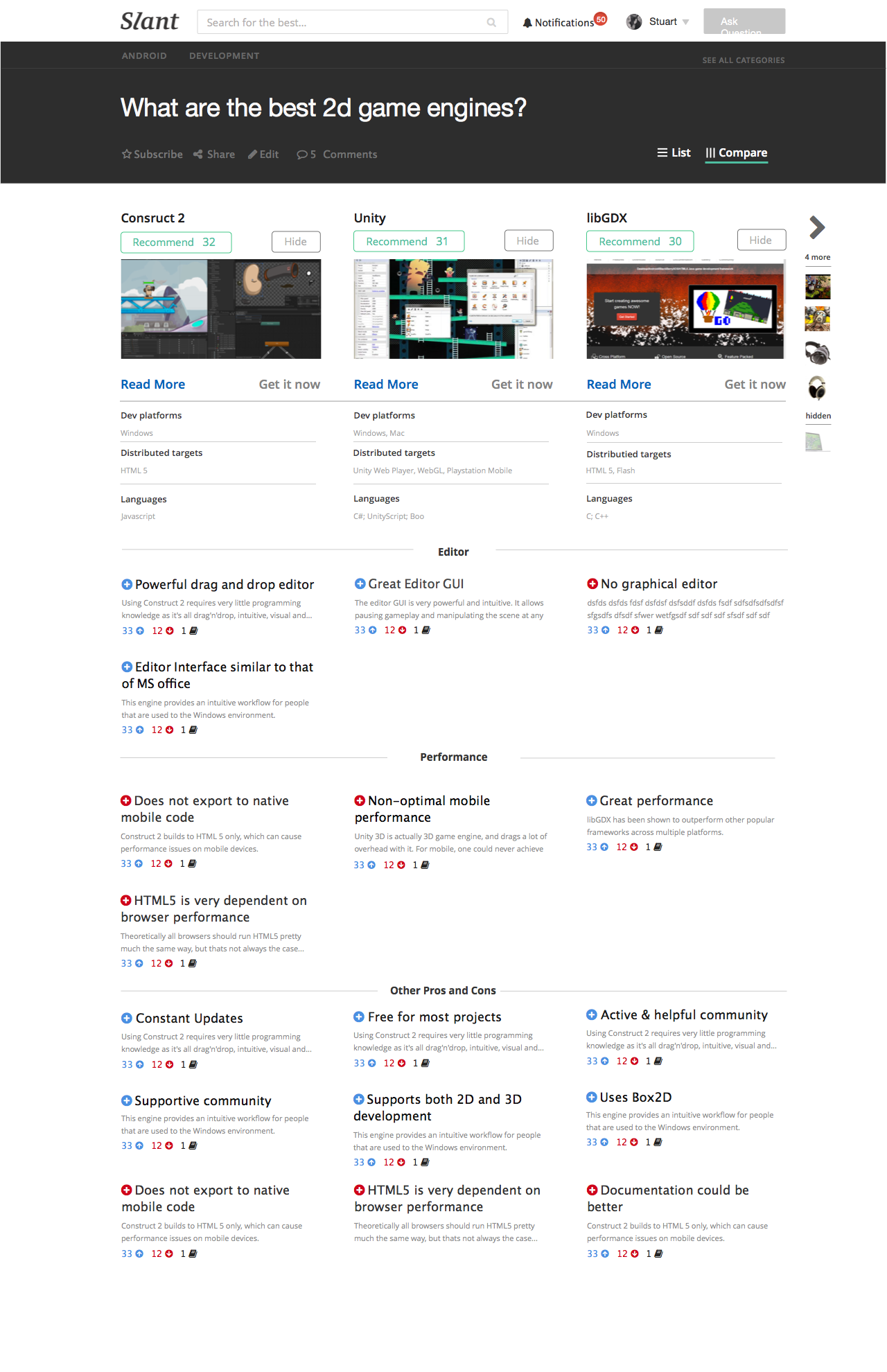
We currently suck at Comparable Qualitative Data. Our pros/cons aren’t directly comparable across options, so we’re doing a terrible job with this one. Try going to “best 2d game engines” and compare the editors of all the different engines. Try going to “programming keyboards” and figure out which has the best build quality. Super important to help people make a decision and we make it very hard.
Some thoughts about this:
-
If Specs taught me anything, it’s that properly structuring the data cleans it up a lot. By moving all the “Is cross platform” Pros into the spec table it made the Pros/cons so much better. The same is going to happen when we fix comparable Pros. All the comparable pros will be places together and this will let the unique pros really shine.
-
“Comparable Pros” will be compared against a set of attributes that belong to the question. For example “Best 2d game engine” would have:
-
Editor
-
Performance
-
Support
-
Ease of use
-
Doing ^ would theoretically let us award options with “Best editor” algorithmically. This would stop all the silly “really easy to use!” titles that are effectively randomly added by users. However if we do this we’re going to need a better way to rank Pros than just vote counts.
-
This is most likely going to be achieved by tagging Pros/Cons with the question attributes and then grouping them.